实验室在多标签因果特征选择方向的研究工作被人工智能领域国际顶级会议IJCAI 2025(CCF A类)录用,论文题目为“MCF-Spouse: A Multi-label Causal Feature Selection Method With Optimal Spouses Discovery”。本次IJCAI共收到5404篇投稿(不含desk reject),最终录用1042篇,接收率为19.3%。该论文第一作者为实验室2023级博士生马琳,通讯作者为吉林大学讲师胡俊成,主要合作者包括MBZUAI博士后黄强和东北师范大学讲师郝娉婷。
研究背景
在现实世界的诸多应用场景中,如文本多标签分类、图像多目标识别、生物医学疾病预测等,每个样本往往对应多个相关联的标签。这类问题被统称为多标签学习(Multi-label Learning),其关键挑战之一是如何在特征空间中选择对多个标签都具有影响的信息。然而,传统的特征选择方法忽略了标签之间潜在的因果依赖关系,影响模型的泛化性能与可解释性。
近年来,因果发现方法逐渐引入到特征选择中,因果特征选择(Causal Feature Selection)开始被研究者关注。虽然已有方法在单标签场景下取得一定成果,但其在多标签场景下的适应性仍面临挑战:
- 标签之间的因果结构更复杂,即存在特征-标签,特征-特征,标签-标签之间的因果结构;
- 单独对每个标签建模容易产生特征冗余或遗漏;
- 多标签场景下因果发现的“忠实性”假设不再成立,即存在多个等价信息;
- 配偶节点的发现过程容易导致大量冗余的条件独立性测试(Conditional Independence tests,CI tests)。
为解决上述问题,我们提出了一种新型的多标签因果特征选择方法——MCF-Spouse。该方法使用互信息比较标签与特征节点对目标节点的贡献度,以此解决等价信息问题,并通过对节点的“V-structure”分析讨论,发现多标签场景下,需要保存的配偶形式,大幅缩短配偶发现所需要的条件独立性测试数量。
实验设计

第一阶段:PC(父子节点)发现。
本阶段采用HITON-PC算法进行目标标签Li的候选PC集CPC的发现,如算法第3行所示。HITON-PC在减少假阳性和假阴性方面表现优异,能够有效提升因果结构发现的准确性。
第二阶段:恢复由标签相关性过强被阻塞的特征。
由于多标签间存在强相关性以及等价信息问题,某些重要特征可能在第一阶段中未被选入Li的CPC。为此,算法第5–10行重新评估了这些被忽略的特征。具体来说:
- 第5–7行:如果特征Fj不在Li的CPC中,则说明其可能因其他标签而被阻断。
- 第8–10行:通过判断Fj与标签Yi是否独立,构建得分序列Fere。从中选取前k1%的特征,作为最有可能被忽略的重要特征。
算法第11–17行进一步识别阻断路径:
- 第11–14行:若在不包含标签Lk的条件下,特征Fj与标签Li依赖,而一旦加入Lk后两者变得独立,则说明Lk阻断了Fj→Li的路径。
- 第15–17行:通过比较互信息I(Li;Fj)与I(Li;Lk),我们量化两者对Li的贡献度。若Fj贡献更大,则纳入Li的CPC;反之,保留Lk。
第三阶段:配偶节点发现。
配偶节点的识别依赖于V结构,根据论文中第三章的讨论,最优的配偶节点仅可能在即Li→Fj←Fk结构中出现。
- 第19–21行:遍历Li的候选PC集中的每个特征Fj。
- 第22–23行:若Fj 同时也是其他特征的PC,则可能为碰撞节点。
- 第24行:候选配偶节点集合为所有不在Li的CPC中的特征。
- 第25行:若将Fj作为条件变量后,发现某特征Fk与Li 产生依赖,说明三者构成V结构,Fk即为Li的配偶节点。
实验结果
在本实验中,我们将所提出的MCF-Spouse方法与9种多标签方法进行了对比。采用ML-kNN进行评估,最近邻数k设置为10。
我们选取了八个来自不同实际应用领域的多标签数据集,分别为:
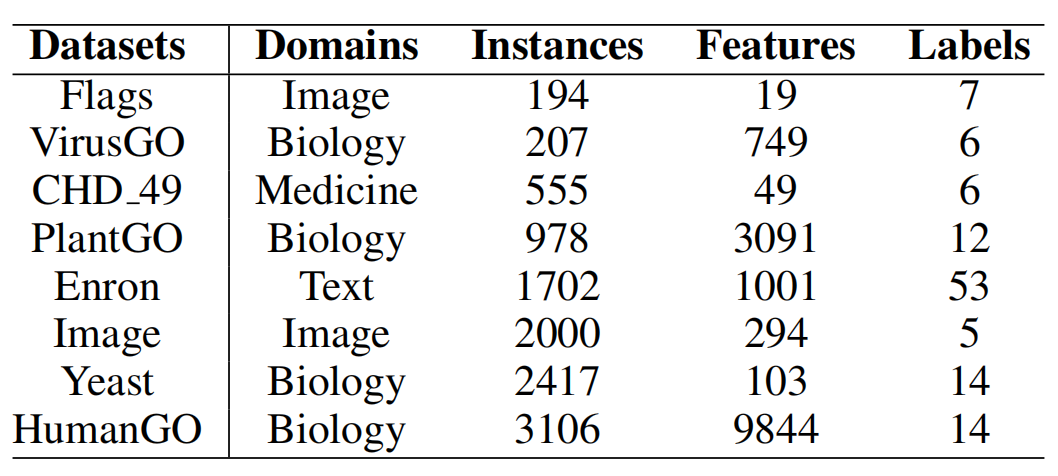
所有数据可从多标签分类数据集库中下载:http://www.uco.es/kdis/mllresources/#3sourcesDesc 。
我们选用以下四项常见的多标签特征选择指标来评估特征子集的性能: Hamming Loss(越小越好),Ranking Loss(越小越好),F-micro(越大越好),F-macro(越大越好)。
结果分析:
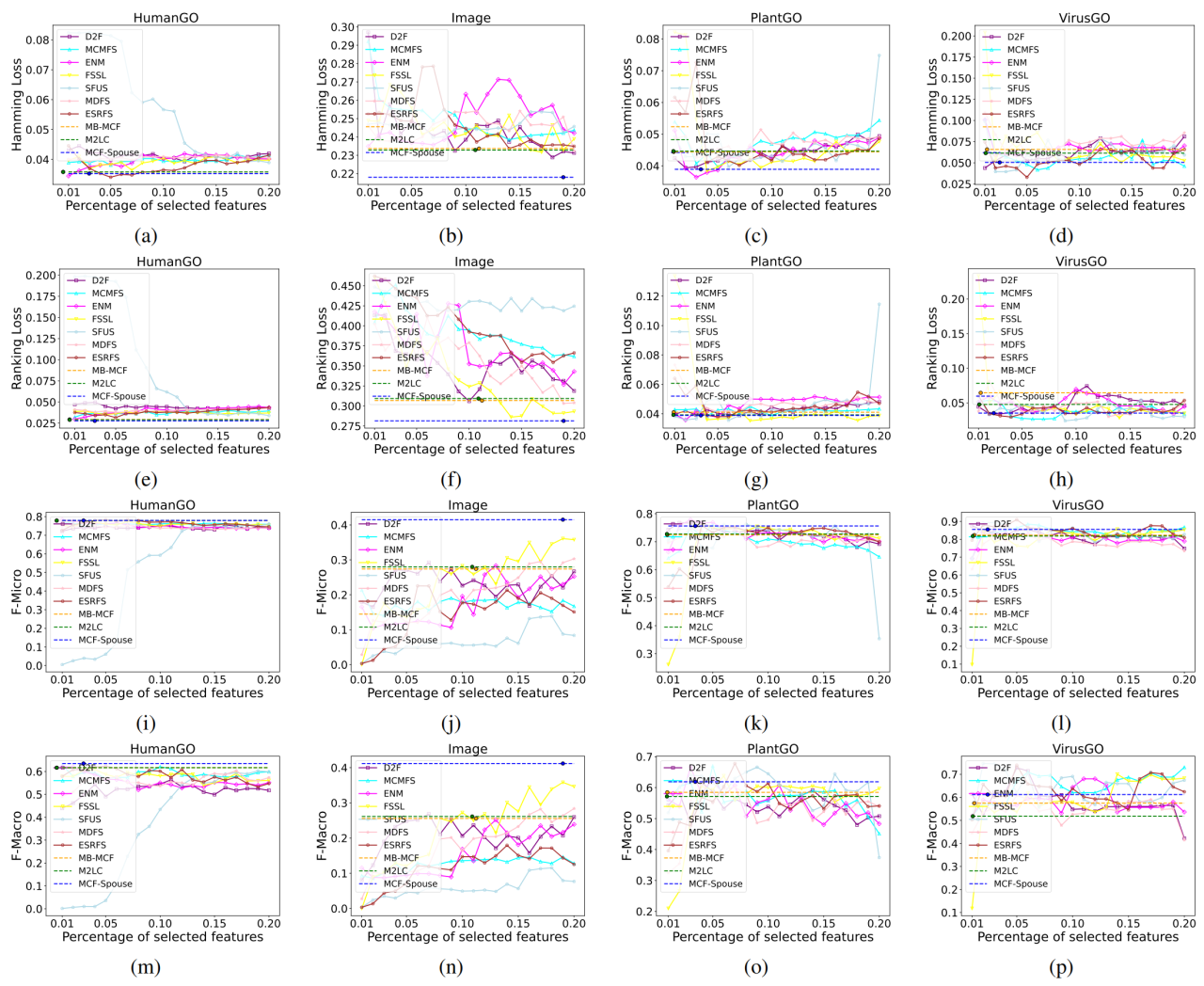
从图1可见,MCF-Spouse方法通过引入配偶变量搜索机制,相较于未考虑配偶变量的MB-MCF和M2LC,选取了更多的相关特征,从而在四个数据集的所有指标上实现了显著性能提升。这表明,配偶变量在提升模型预测能力和准确性中起到了关键作用。
与通过逐步调整特征比例(每次1%)来寻优的非BN方法相比,MCF-Spouse不仅在大多数数据集上表现更优(仅在VirusGO上F-macro稍弱),而且具有更强的稳定性和更高的效率。相反,非BN方法通常表现不稳定,且需要大量时间完成搜索。
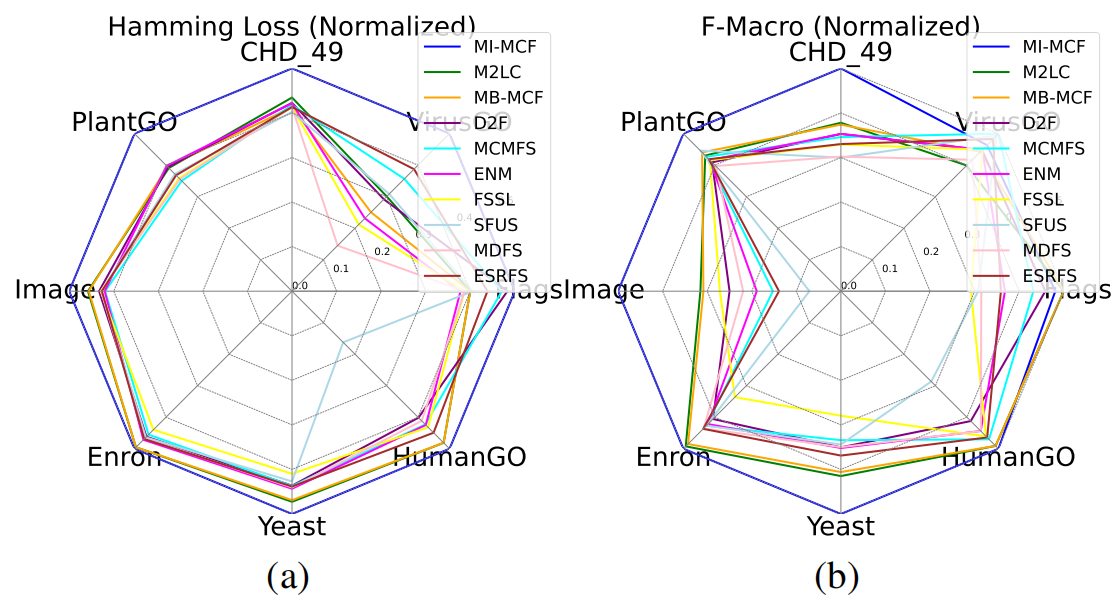
为了进一步验证MCF-Spouse在不同指标和数据集上的稳定性,我们将各方法结果归一化到[0,0.5]区间,并赋值最优方法为0.5。对于HammingLoss等越小越优的指标,归一化最小值为0.5;对于F-Macro等越大越优的指标,归一化最大值为0.5。如图2所示,MCF-Spouse呈现出近似正八边形的表现,说明其在多个数据集和多个指标下均具有稳定性。
运行时间分析:

我们在Flags与Image数据集上对这10种算法进行了运行时间评估,计时从算法开始执行到使用ML-kNN完成分类为止。为保证公平性,对于非BN类方法,我们将运行时间取其在1%到20%特征比例下的平均值。
如表所示,MCF-Spouse在运行效率上表现优越。在Flags数据集上,其运行时间与MCMFS、ENM相当;而在更大的Image数据集上,相较于MB-MCF、MCMFS等方法,MCF-Spouse显著缩短了运行时间。这表明MCF-Spouse能在保持高质量特征选择的同时,兼顾计算效率,适用于高维复杂任务。
IJCAI 2025全称为The 34th International Joint Conference on Artificial Intelligence,将于2025年8月16日至22日在加拿大蒙特利尔举行。IJCAI是人工智能领域最具影响力的国际会议之一,与 AAAI+ 和 NeurIPS 并列,是发表人工智能领域前沿研究的重要平台,也是中国计算机学会(CCF)推荐的A类国际学术会议。会议内容涵盖了人工智能理论与架构、机器学习、自然语言处理、计算机视觉、机器人科学等几乎人工智能的所有核心领域。