实验室物联网数据挖掘方向工作被ESWA(中科院一区)接收,论文题目为“User intention prediction for trigger-action programming rule using multi-view representation learning”。该论文提出一种名为MvTAP的触发-动作编程(TAP)规则用户意图预测方法,利用多视图嵌入技术学习用户创建TAP规则背后的意图,以提升规则推荐的多样性,是实现智能家居、智慧城市等物联网智能化应用的关键技术。该论文第一作者为实验室2020级博士吴刚,通讯作者为吉林大学副教授王峰,其他合作者包括吉林大学教授胡亮、2022级硕士胡喻晓和2020级博士邢永恒。
研究背景
TAP规则用户意图预测旨在推断用户创建规则背后的隐性意图,从而提高TAP规则推荐的多样性,是智能家居平台、自动化工具或规则推荐实现更高智能化和用户体验的关键组成部分。然而,预测用户创建TAP规则背后的意图存在三个问题:
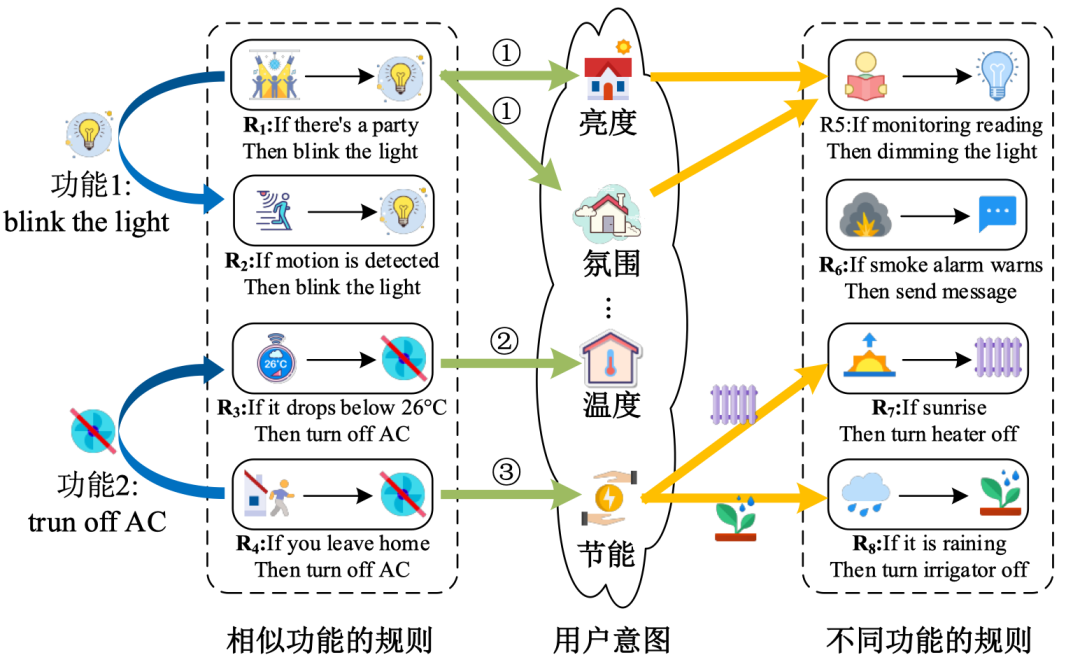
- 触发器和动作之间的上下文依赖关系导致用户在组合不同功能时会产生多种意图。例如,规则“人离开时关灯”体现了节能的意图,而“日出时关灯”则更多体现了光照调控的意图,尽管二者具有相似的动作,但其背后隐含的用户意图却显著不同。
- 触发器与动作通常仅以简短的文本描述呈现,造成意图边界难以精准识别。这类描述在语义层面存在高度压缩,导致模型在解析用户需求时面临较大困难,尤其是在缺乏上下文补充信息的情况下尤为明显。因此,如何在简短的功能描述中准确识别用户意图是一个挑战。
- 实体之间缺乏常识知识使得实体相关性的发现受到限制,导致跨功能自动化的局限性。例如,空调和风扇虽然属于不同类型的设备,但它们具有相似的功能(如制冷)和使用场景(如卧室)。
为了应对以上挑战,研究团队提出了一种基于多视图嵌入的物联网TAP规则用户意图预测方法MvTAP,通过从用户视图、开发者视图和知识视图中学习规则的嵌入向量来预测用户意图。其次,分别应用了MPNN、TextCNN和RKE来学习用户视图、开发者视图和知识视图的嵌入向量,并提出了一种基于Transformer的多视图嵌入融合方法,以有效整合这些嵌入向量,保存全局和局部信息。
实验设计
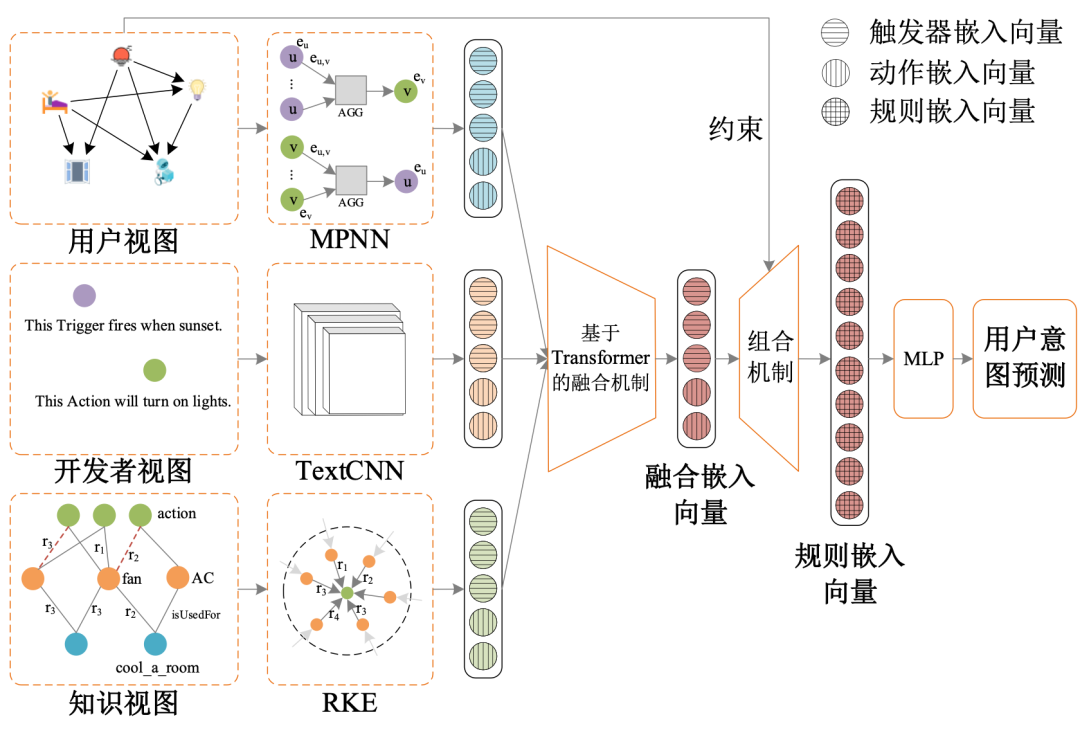
基于多视图嵌入的物联网TAP规则用户意图预测方法包含以下五个主要模块。如上图所示:
- 用户视图嵌入:该模块基于用户创建的触发-动作对构建用户视图。为编码用户语义信息,采用MPNN对用户视图进行学习,生成触发器和动作的嵌入向量。
- 开发者视图嵌入:该模块以开发者提供的触发器和动作的描述文本为输入,利用NLP技术(即TextCNN)学习触发器和动作的句子级嵌入向量。
- 知识视图嵌入:该模块将与触发器和动作相关的实体映射到外部知识库(即ConceptNet),建立从实体到知识图谱概念的链接。随后,采用RKE方法,基于知识图谱聚合语义邻居的嵌入向量,学习知识增强的触发器和动作的嵌入向量。
- 多视图嵌入融合:该模块引入基于Transformer的融合方法,将从上述三种视图学习到的触发器和动作嵌入进行融合,并在用户视图约束下结合,生成TAP规则的嵌入向量。
- 用户意图预测:该模块以TAP规则的嵌入向量作为输入,预测每条规则对应的用户意图。
实验结果
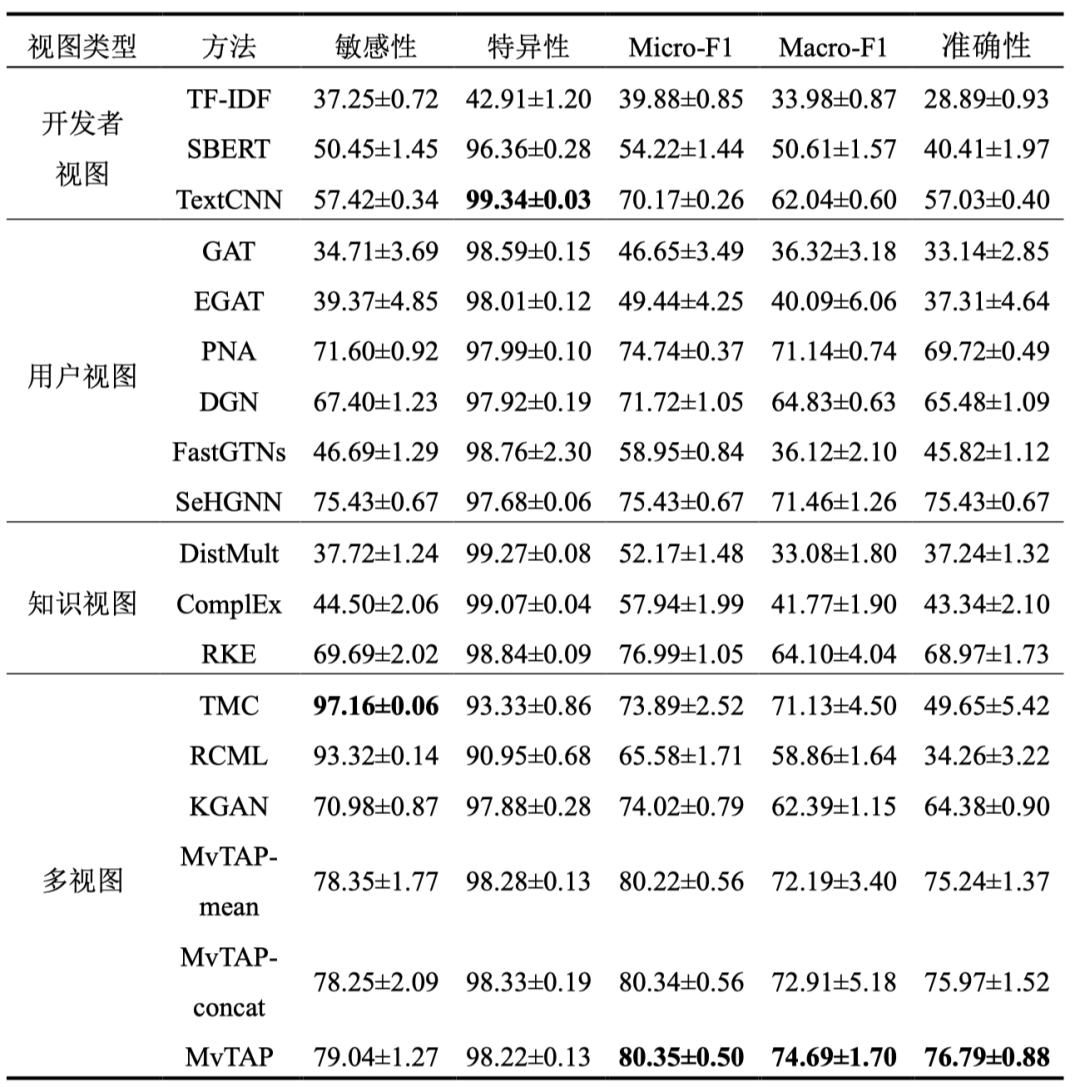
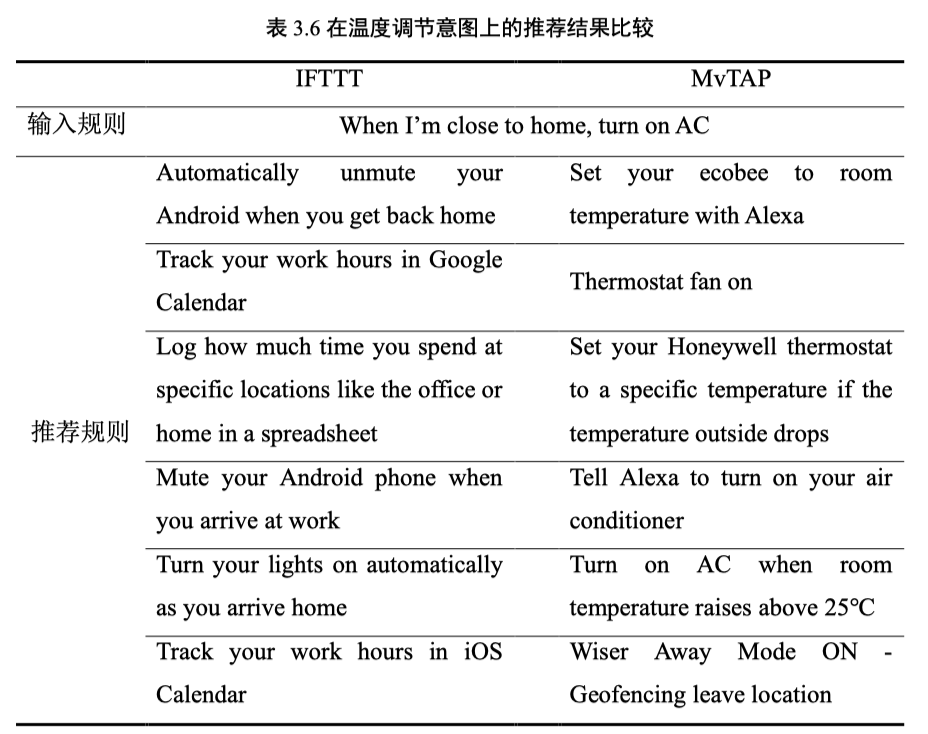
实验在IFTTT数据集上进行,首先对比了MvTAP与GAT、SeHGNN、KGAN等15种对比方法在TAP用户意图预测任务上的有效性,然后展示了MvTAP在TAP规则上的表现。实验结果表明,在TAP规则用户意图预测任务方面,提出的MvTAP方法在准确性、Micro-F1和Macro-F1指标上表现优异,较现有最优方法分别提升了1.8%、4.36%和4.52%。与单视图方法相比,MvTAP的准确性分别比开发者视图、用户视图和知识视图中表现最好的方法提高了34.65%、1.8%和11.33%。与效果最好的多视图方法相比,MvTAP在准确性、Micro-F1、Macro-F1和特异性指标上的提升分别为19.28%、8.55%、5%和0.35%。此外,MvTAP在准确性、Micro-F1和Macro-F1指标上的表现也优于其变体方法。另外,在TAP规则推荐任务方面,相较于IFTTT平台,基于MvTAP预测的用户意图来推荐TAP规则实现了更高的优越性。
ESWA全称为Expert Systems With Applications,是人工智能领域的重要国际期刊,专注于人工智能理论方法研究及实践应用。该期刊由Elsevier出版,在JCR和中科院分区中均具有较高评价,影响因子稳定在7.5以上,审稿周期约13.8个月,是闭源期刊。其核心研究领域覆盖专家系统、数据挖掘、物联网等前沿技术,尤其注重方法应用创新。